国内数据库技术盛会——2017第八届中国数据库技术大会(DTCC2017)于2017年5月11-13日召开,大会吸引120多位技术专家分享、5000多名IT人士参会,在5月11日的大会中,腾讯云数据库高级工程师,PostgreSQL数据库专家许中清做了腾讯云Postgres-XZ数据治理经验分享。
从微信支付在实际案例中,许中清介绍了腾讯云分布数据库DCDB for Postgres-XZ在数据治理过程中面临的数据倾斜、成本优化、数据迁移等能力,以及在解决这些问题的过程中Postgres-XZ的一系列优化和内核优化,包括映射关系表(shardmap)、虚拟节点组、多维分片策略、不停机数据搬迁等功能。

腾讯云分布式数据库DCDB系列产品,对内支持腾讯内部业务的发展,对外为企业提供强有力的服务,已经赢得广泛客户的信任与口碑,积极推动了腾讯云的快速发展。
一、简介
Postgres-XZ是腾讯自研的,基于MPP架构分布式关系型数据库集群,内部代号为PGXZ。PGXZ是面向OLTP应用,兼容PostgreSQL协议,支持分布式事务和跨节点复杂查询的一款分布式数据库。目前已经在微信支付商户系统中运行近3年,管理超过230个节点和400T的数据量,也是全球最大的PostgreSQL集群之一。
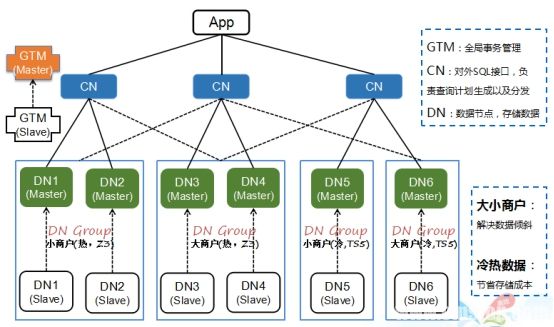
PGXZ的架构如下图,其中GTM负责分布式事务管理,DataNode负责存储数据,Coordinator负责对数据进行分发、聚合等操作,Coordinator本身不负责保存业务数据。Coordinator通过将分布Key上值进行Hash路由到各个DataNode上。
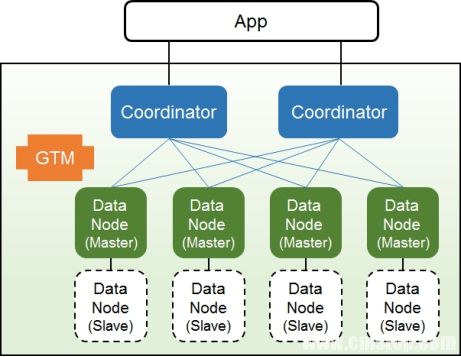
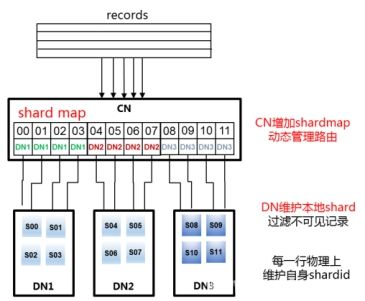
另外,PGXZ引入了逻辑路由层,在Coordinator上实现映射关系表(shardmap)。数据分布关键字(Distribute Key)先被Hash出ShardId,然后用ShardId查询ShardMap表找到数据对应的DataNode。路由过程如下图:
二、防数据倾斜
但凡是分布式集群,数据分布不均衡和负载分布不均衡就天然存在,这叫做数据倾斜;数据倾斜导致会负载和数据集中在一两个节点,进而严重影响集群的扩展甚至正常运行。解决数据倾斜,是数据治理的最主要目标之一。
通过分析,我们发现数据倾斜的主要原因:分片关键字(Distribute Key)本身引入的倾斜:因为业务数据本身的特征,导致在某个分布Key值的记录数特别多,例如交易类业务,以账户ID作为关键字,然而某账户ID交易量特别大,也会导致数据倾斜。
首先,通过管理shardmap,PGXZ确保数据均匀的写入DataNode。同时,通过shardmap的动态管理, PGXZ可以动态将部分数据从负载较高的节点迁移到负载较低的节点,进而保证进一步的均衡。当然,这里的分片策略不仅仅是来解决倾斜。
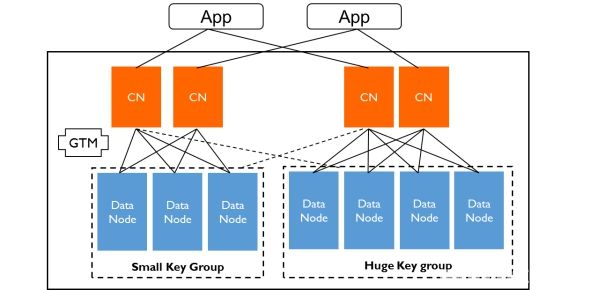
某些特殊情况,例如大多数业务存在2/8原则,即前20%商户可能产生超过80%的交易和数据,银行业务、社保业务、电商业务都存在类似情况,我们实际应用中也发现,微信支付系统中的京东账户,采用动态迁移数据本身已经无法解决数据倾斜的问题了,因为京东账户的数据量和负载要求甚至超出一个DataNode物理上限。PGXZ为了解决这种问题,引入了虚拟节点组技术,即由多个DataNode组成一个(或多个)虚拟的DataNode(组),来承载那仅有20%商户产生的80%的交易和数据(如下图Huge Key Group)。
三、冷热数据分离
在数据治理过程中,成本一直是我们关注的地方。由于分布式集群本身设备采用x86服务器,相对于某些方案,成本已经很低了。但PGXZ并不满足,因为腾讯内部PGXZ集群规模还在快速增长,我们可以预见突破1000台设备之日可待;而这么大规模,全部采用高端x86设备,成本也是非常恐怖的;因此,我们提出了在数据库层的冷热数据分离,降低存储成本的方案。
在大部分数据库系统中,数据有明显的冷热特征。显然当前的订单被访问的概率比半年前的订单要高的多。根据经验来讲,越是数据量增长快的系统,这种冷热特征越明显。将冷数据存储到带有大容量磁盘的服务器上,将热数据放在价格更昂贵的ssd上明显更合理。传统方案是通过拆解系统,但PGXZ通过将冷热数据分布存储到Cold Group/Hot Group来大幅度降低硬件成本。
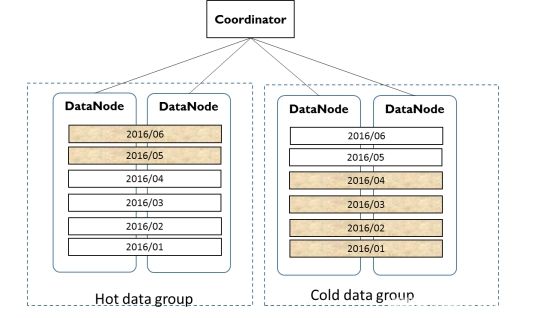
以下图架构是一套完整的架构举例,我们将PGXZ将DataNode从冷/热、大Key/小Key 两个维度分成四个:
Group:Small Key Group(Hot):存储小Key、热数据;
Small Key Group(Cold):存储小Key、冷数据;
Huge Key Group(Hot):存储大Key、热数据;
Huge Key Group(Cold):存储大Key、冷数据
每一个DataNode Group都有独立的ShardMap空间(shard到datanode的映射表);每一个DataNode Group都有不同的Hash策略。比如,对于每一个record,Coodinator(CN)首先会根据DistributedKey和create time判断该record路由到哪一个group。然后采用这个group内的hash策略、并查找这个group的shardmap进一步路由到某一个DataNode。
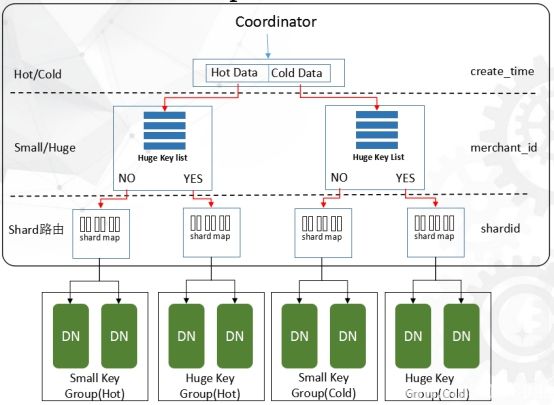
Coordinator首先根据record的create time判断是冷数据还是热数据,然后查询Huge Key List(PGXZ也提供接口由用户指定)判断record是属于Small Key Group还是 Huge Key Group。最后在指定的Group里面通过hash和查找ShardMap找到对应的DataNode。
为什么每个Group采用不同的Hash策略?最直接的原因就是2/8原则让关键字(Distribute Key)本身引入的严重的分布不均匀。因此在Big Key Group我们通过(distribute key, create time)复合列将大商户的数据hash到不同的shard,保证超大商户能够存储到集群中。那么,为什么小商户不统一使用这种多列的hash策略呢?因为对于数据量小的商户,路由到一个DataNode可以避免对单个账户写操作时的分布式事务和读操作时的跨接点查询。最后,Small Key Group(Hot/Cold)的Hash策略完全一样,Huge Key Group(Hot/Cold)的Hash策略也完全一样,只是他们各自属于不同的shardmap空间。
四、在线迁移能力
解决了倾斜问题,我们看看看自动扩容/缩容,越是发展快的业务,越是重视如果不影响业务运行快速扩容/缩容。当集群规模不足以支撑业务量的增长时,需要增加新的节点,PGXZ会自动将一部分shard从原来的Datanode无缝迁移到新节点上。或者当节点数据出现倾斜时,系统自动将shard从负载较高的节点迁移到负载较低的节点。那这是怎么做到的呢?
通过以上描述了PGXZ集群中的数据分布策略,我们分析可得到在PGXZ中,有三种类型的数据迁移:
热数据变冷,迁移到Cold Group。这是跨Group迁移
小账户变大,签到 Huge Key Group。这也是跨Group迁移
扩容或者因为均衡的原因,在一个Group内部的节点之间进行迁移。
而对PGXZ数据迁移的目标是:
不影响业务。
保证数据完全一致。
综合上述要求,PGXZ提出了一系列解决方案。对于扩容来说,加节点操作很简单,但真正的难点和重点是,再保证高可用和数据一致性的基础上,不停机就能完成数据的迁移。PGXZ的解决方案是根据迁移目标,设定一系列任务(Shard Moving Task)关键点,并对这些关键点进行拆解分析并加以实现。
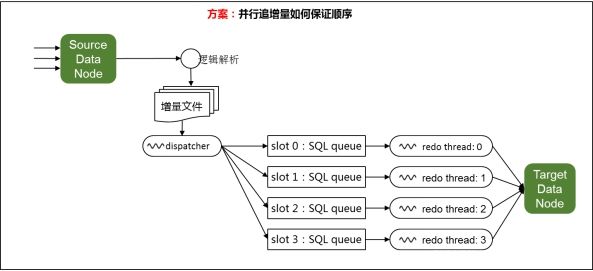
一个分布式迁移任务(Shard Moving Task)由一个三元组(源source, 目标target, 分片Shards)来定义:从源节点迁移分片中的数据到目标节点。整个流程一共分成5个大步骤:迁移存量数据、迁移增量数据、数据检验、切换路由、清理(如下图):

迁移存量:顾名思义,就是将需要搬迁的分片的存量数据从源节点搬迁到目标节点。此时业务依然在写,为保证二者存量数据迁移不会存在重复或遗漏的数据?PGXZ的方案是是将开始导出存量数据和开始记录增量这两个动作使用同一个数据库快照(Snapshot)。这里要说明下,在路由切换之前,这些目标节点中的数据对外不可见。

追增量:为确保重做增量数据的同时,新的增量数据写入顺利,PGXZ采取多轮迭代的方式来追增量数据。每一轮的增量数据会越来越少(搬迁的速度比新增的速度快),因此每一轮迭代的重做时间逐轮收敛,直到收敛到某一个可配置的阈值,我们就进入下一个步骤数据校验。
数据校验:PGXZ支持严格的数据校验,要求迁移后,不仅数据条数一要致,而且内容也必须完全一致。但是传统的校验需要花费很多的时间,而且,为了保证源节点数据不再新增,必须有一个加锁(只读)的过程。PGXZ的方案是,不是等到源节点统计完成之后才解除阻塞,而是统计校验语句获取快照解除阻塞;因此,所以这个加锁的时间并不长,通常在5ms以内
再追变更:如果数据校验的时间较长,这段时间源节点上又会产生较多增量数据,因此流程需要再次追变更,过程与第二步中的追变更完全一样,在某一轮迭代的重做时间达到某个阈值时,开始进入下一步:切换路由。
切换路由:切换路由需要加锁,也就是阻塞源节点上对这些迁移的分片的写操作,业务在这些分片上的写操作会失败。在路由切换完之后再解除源上的写阻塞。需要注意的是,在阻塞写的这段时间,切换路由之前,还有最后一轮增量迭代需要在目标节点上重做。根据我们在现网中经验,这段阻塞部分shard上写的时间绝大部分情况在20ms以内,通常可以做到小于10ms。,而且由于扩容时,并非所有节点数据都去做迁移,因此这个影响也有限。
清理:解锁、停止源节点上的记录增量数据的过程,清理源节点上的重复数据。
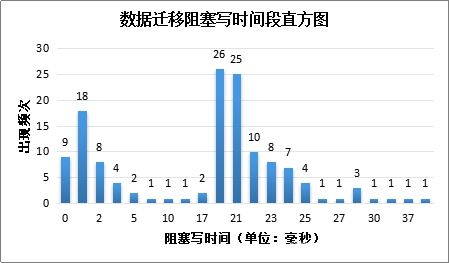
最后根据我们在微信支付多次扩容操作中的统计,主要关注每次迁移锁读写的时间,我们一共进行了135个迁移任务。每一次切换路由时锁业务的时间主要分布在20ms~25ms之前,平均阻塞时间时15.6ms。总的来说,大家感受到的微信支付等一系列服务几乎是全年无休的持续服务的,也注意证明,我们PGXZ的迁移等运维操作,几乎是对业务没有影响的。
根据我们的经验来看,在一个分布式机器的运维过程中,除了日常巡检和故障排除以外,大部分的自动运维工作都在数据迁移上;比如扩容搬迁、冷热数据搬迁等等;因此,如果能使用云服务,例如腾讯云的关系型数据库CDB,分布式数据库DCDB等,这类工作极大的简化,不仅提升每一个业务的效率,还能让大家更加专注于业务开发,提升业务价值。
以上就是PGXZ数据治理策略的主要内容。