4月25日-26日,企业网D1Net《2017CCS云计算渠道合作高峰论坛》在京举行,易观国际CTO郭炜以《Pb 级大数据集群云化与迁移》为主题,分享了其大数据迁移过程中遇到的问题及采用的解决方案。
提升云迁移中数据互传效率
云迁移通过互联网互传的时候,小包传没有效率,易观使用自建的“四分卫”的开源项目有效提高了云迁移的高效数据互传问题。易观开源的“四分卫”类似橄榄球的传球手,运用压缩算法和排序将每个小包压缩成一个档案,通过互联网传到两个接收端,解包后按照排序再进入到Kafka里面,通过排序、互传同步的机制,保证不丢包。假如发生丢包,也可以续传,然后再放进Kafka。
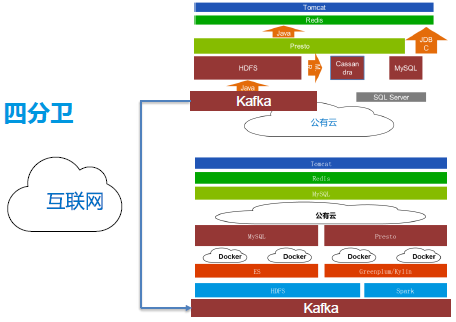
(四分位架构)
实现海量数据并发
郭炜认为,Pb 级大数据迁移首先要有良好的扩展网络架构;其次,要有云+端的控制策略。
1.在良好的扩展网络架构方面,应使用混合云,而不仅仅是私有机房。原因在于混合云有两大优势,一方面混合云支持接受端公用云弹性扩展、网络带宽、接收性能、安全防控,可以防止第一波安全相关的问题;另一方面混合云下端的大数据集群可以满足实时计算、高耗CPU、高内存、Hadoop版本提升等需求。
2.在云+端的控制策略方面,在郭炜看来,云+端的意思是在做数据处理的时,除了上传到云端,还应该在云端部署策略。一旦云端出现无法处理数据的情况,可以要求客户端暂停传输,或者选择4个小时或2个小时以后再传。当发现某个恶意设备,可以实施暂停命令,让其进入黑名单静默。另外云端策略还包括清洗策略、分流策略等。
30秒得出计算结果
“面对几百亿的用户数据,用户想看到的统计值是怎样的,希望30秒看到结果。”郭炜介绍说,面对客户这类的需求,易观最终做了两件事,一件是启用了最新开源的Greenplum大数据计算引擎,该架构加速了数据并行计算;第二件事是对利用分析师给出的模型,针对目标数据进行分层抽样,目前能使用户体验到20秒看到几亿用户的行为数据结果,误差在5%以内。
(开源+抽样解决方案)
解决漏斗查询难题
对于很多企业来说,从浏览网页到产品下单到支付的转化率和流失率,对业务发展至关重要。业内将这种场景称为“漏斗查询”,在郭炜看来,漏斗查询的难点在于,需要对一个有序行为序列转化漏斗。目前市场上大部分的开源引擎都是针对无序OLAP查询,有序的查询相对较难。对此,易观针对该场景给出了解决方案,目前针对百万日活的APP漏斗查询都在30秒以内,近期也会开源给大家。
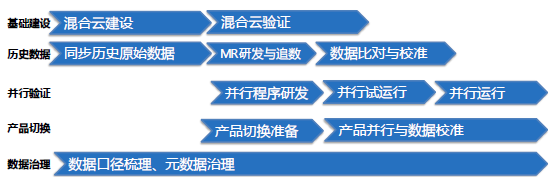
(大数据迁移总结)
郭炜总结说,大数据云迁移,包括几个方面:基础框架建设、历史数据迁移、并行数据验证、产品切换以及业务上面的数据治理几个部分。攻克文中的几个难题,易观国际PB级历史数据得到了无缝切换。目前易观混合云大数据平台有着4.42亿月活量,3000多万日活,累计装机量18.2亿,在互联网行业大数据中也处于第一梯队。